2.1. Git overview¶
In this section we go over some basics to help get a mental picture of what is happening when we use Git.
2.1.1. What even is Git?¶
Git is a tool used to keep track of files that change over time. It excels at tracking differences in text files (e.g. pretty much any code, regardless of the language or file type). With a little guidance, it can be used to make snapshots of your files that you can later revert back to, track changes made by you or others, and allow collaborators to merge different versions of the same files.
While the inner-workings of Git are mostly left out for brevity, it’s worth noting that Git has very low overhead (i.e. it is very space efficient). You could imagine that snapshotting a whole folder on your computer - or even your entire computer - several times per day might require lots of extra hard drive space. This isn’t true when using Git, where years-old projects with thousands of snapshots are typically not much larger than the folder being tracked. This is achieved through the clever algorithms built right into Git (there are many good explanations online if you are interested in learning more about the inner workings of Git).
2.1.2. Git Repositories¶
A Git repository (repo for short) is simply a directory (i.e. folder) that is “tracked” by Git. Any old directory can be turned into a Git repository with the git init command. This command makes a hidden .git folder in your directory which Git will use to see if any changes are made in the directory. That’s it.
Git users often use repo synonymously with project since the repository generally contains all of the files needed for a single project that you’re working on. So even though it’s just a plain old folder, you can sound technical if you type git init and start calling your projects repos.
2.1.3. Git Commit¶
The backbone of everything that Git does, you can think of a Git commit as a snapshot or checkpoint of your repo. Git doesn’t have an auto-save feature, so we’ll learn in the next chapter how we tell Git to make a new snapshot with commits.
Commits are great because they allow you to go back to an old version of your repository exactly how it was when you made the commit. They even force you to leave a helpful commit message that can jog your memory as to what you were changing all that time ago. Accidentally deleted a file? Did you break a piece of your code that you know was working last week? You can go back to last commit that worked and see what changed since then, all without discarding the changes you made since then.
One important note is that, since you have complete control over when to make commits and what message you leave to describe your commit, it’s useful to commit often and leave useful commit messages.
Good commit messages
Take a walk with me to the year 2021 (or <current_year>+2 if you’re joining us from the future). You’ve been tracking your research in a git repo and a collaborator asks for a function, awesome_func() that you remember writing about 2 years ago. The problem is you deleted that function because you didn’t need it. Thanks to the magic of git, you should have a checkpoint with it somewhere…
When you look at your commit history, or git log (we’ll learn how to do this next chapter!), which would you rather see?
s87f6s9 - I added stuff (Thu Nov 1, 2018)
klh54as - deleting stuff (Fri Nov 30, 2018)
f984jst - whoops (Sat Dec 1, 2018)
un23hc8 - adds a whoooole lotta stuff from December (Fri Dec 28, 2018)
Or:
s87f6s9 - Add awesome_func() to improve performance of slow_func() (Thu Nov 1, 2018)
klh54as - Fix a bug in awesome_func() that made it crash (Fri Nov 2, 2018)
f984jst - Remove awesome_func() because I don’t need it (Fri Nov 9, 2018)
un23hc8 - Added plotting to even_better_func() (Tue Nov 13, 2018)
In the second example, we can see the exact date that we removed awesome_func() and can easily go find it, all because we left a useful commit message all those years ago. Future you thanks you!
Committing like a pro
An important part of the “philosophy of Git”, or Gitflow is making commits that don’t change too much at a time and are retrievable later. Some guiding principles that will have you committing like a pro in no time:
Commit often
Leave descriptive commit messages
Make commits atomic (single units of work)
1: How often depends on your work. When in doubt, commit more.
2: Descriptive messages can save a lot of headache later. This is an easy habit to make if you start off with it, while leaving short, unintelligible messages is a hard habit to break. Sidenote: Convention is to start the commit message with a singular verb (“Add…”, “Fix…”, “Revert…”, etc).
3: Commits are like the building blocks of your repo. If a mistake slips into your code in an enormous commit, it will be much harder to find that mistake later than if you commit in small, single units of work. This is the hardest of the 3 guidelines and takes a bit of practice. When in doubt, ask yourself: “Does this commit add/change/fix one thing?” If not, consider splitting it up into 2 (or more) commits.
2.1.4. Git Branch¶
Git repos start out with one main branch called master. Branches are used to split off from the master history for awhile, usually to work on some part of the code that might break things in master. When that new code is ready, it can be merged back into master. This may be a little hard to visualize, so let’s look at a picture!

Here, the master branch is in gray and is the main “timeline” of the repo. John Doe splits off a new branch called develop in order to work on a feature that they do not want to be part of the main code yet. After working on develop for awhile without affecting any files in master, they merge develop into master, so that all those new changes are now in the main “timeline”. You can also branch off of a branch like the innocuously named John Feature does to make a “New cool feature” on a branch called myfeature. This also eventually gets incorporated into master, and Git handles all the nitty gritty of merging 3 different versions of the repo split off at different times and bringing them into one main timeline.
Ok, but why should I branch?
Say you have a program code.py that reads a bunch of numbers from a text file and does some math on them. This code works and you’re happy with it, but you want to also be able to read from Excel spreadsheets. You might be worried about breaking your code while you add this new feature. Without Git, you could make a copy of your code called code_excel.py and add the functionality. You get it working but you had to change code.py a bunch and now you have two different programs to do almost the same thing.
This is where branches come in. If, instead you make a branch in Git called import-excel. Now when testing your new feature in code.py, you don’t have to worry about ever breaking the master version of code.py. In the meantime, even before your new feature is working, you can continue to use your perfectly good code.py on master just by switching branches. When the new code.py is ready and you’ve tested it on both Excel and text files, you can merge import-excel back into master, having never broken any functionality in your master branch.
Branching when collaborating
The Gitflow guidelines for branching when working with others are:
The
masterbranch should always workAll changes (new features, bug fixes, etc) should be made on their own branch to ensure that you don’t accidentally break the master branch
When your feature is ready, a collaborator should review your changes to ensure they do not break
masterwhen merged inAfter code review and incorporating feedback, the feature can be merged back into
master
These guidelines should help ensure that the master branch is always in good working order and usable by you, your collaborators, and anybody else who needs to use your code. Bugs are annoying and Git branches can help reduce the chances of bugs sneaking into code when collaborating with others.
2.1.5. Git HEAD¶
The shorthand HEAD tells Git where you currently are in history (which branch and which commit). Usually you’re at the end of a long string of commits that started when you first typed git init. When you make a new commit, HEAD moves with you to that commit. When you undo a commit, HEAD moves back to the last commit. If you jump back in time to an old version of your repo to see what was happening then, it is HEAD that lets Git know exactly which snapshot you’re at.
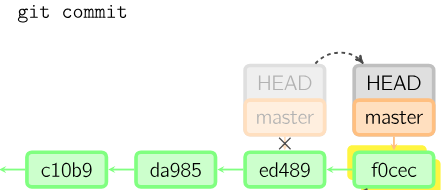
A common error that Git can throw at new users is error: detached HEAD. While it sounds kind of morbid, this simply means that Git got lost somehow (e.g. if you deleted the branch you were currently on), and it doesn’t know where you wanted to point HEAD to next. From here you can simply use the same command we’ll use to move around git history (git checkout) to move to any of your existing branches and re-attach your HEAD.
2.1.6. Visualizing Git¶
The Git diagrams in this chapter were borrowed from A Visual Git Reference by marklodato on GitHub and Git Graph.js. Both can be useful visual references for seeing what Git commands do.